




Пристанище Дата Сайентиста
Канал Рената Алимбекова (@alimbekovkz) про карьеру, применение и обучение Data Science. Веду блог https://alimbekov.com
По вопросам рекламы на канале обращаться к менеджеру: @hey_renataa Related channels | Similar channels
6 157
subscribers
Popular in the channel
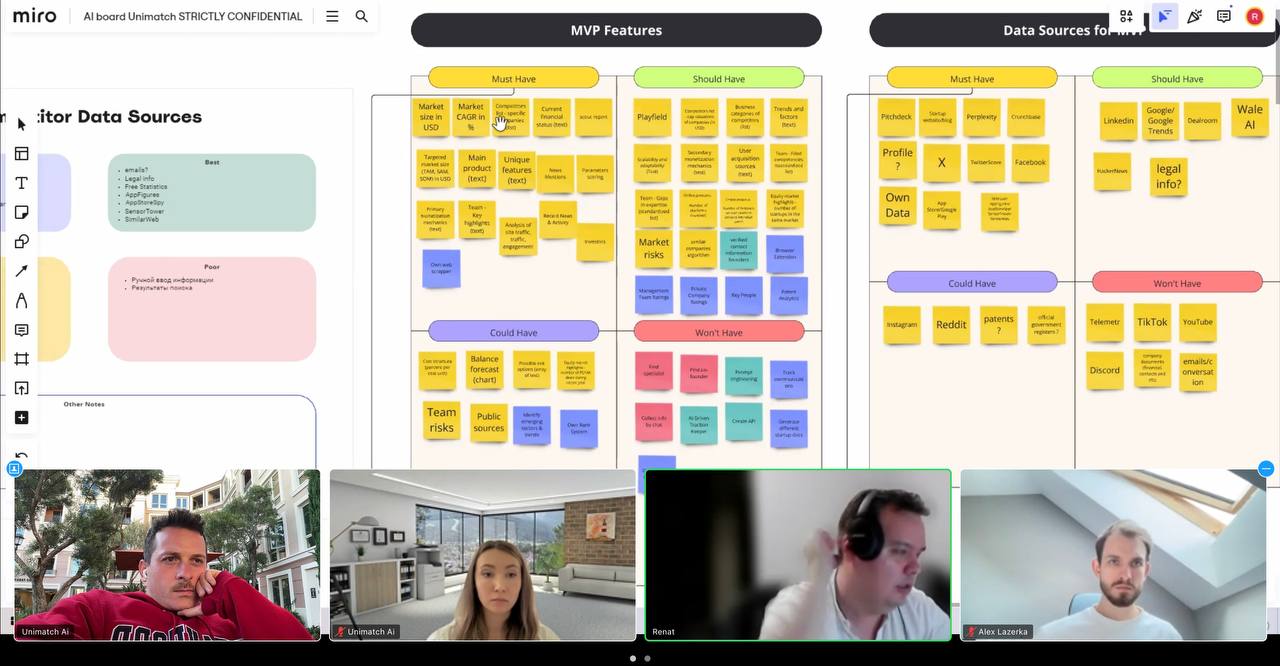
В предыдущем посте писал, что у меня новый карьерный этап. С недавних пор помогаю ребятам из u...
Менторство, помощь в карьере, запуск пет-проектов и поиск фриланс заказов Разговоры о Data Scien...

#llm Очень сильно рекомендую посмотреть трех часовой мастер класс от Sebastian Raschka по импле...
Prompt engineering от Anthropic Вышло интересное видео, где ребята из Anthropic дают практически...

Зарплаты data-специалистов за три года выросли на 40% Kolesa Group провели третье исследование...